谷歌分析GA和站长工具GSC的数据为什么老是对不上?
大家可能有发现谷歌分析GA或GA4(方便起见,下文统一称为“GA”)和谷歌站长工具GSC(google search console)的数据会不同。
这是因为这两种工具处理的是不同的问题。而且它们在数据收集方面也是用不同的方法。
之前收到了不少读者的相关提问,所以图帕先生也主要从这两大方面尽可能简明地解释它们的数据为什么会不同,以及说下我们该采用哪方的数据做参考比较好。
谷歌分析GA的目的GA提供的数据主要在从用户的参与指标(页面停留时间等)、转化相关目标以及用户行为等方面来反映网站的质量。
所以我们可以在GA看到这类报告:
- 转化
- 网站流量数据
- 会话质量、互动情况
- 用户在网站上的行为
等等。
所以可以说GA衡量的是网站的整体质量。
而GSC主要用于网站在搜索上的表现:
站长工具GSC的目的GSC主要是帮我们了解网站在谷歌搜索中的表现。
比如页面索引,即收录——页面收录了才能有排名。
GSC还是能展示更多关于网站自身的问题(而不是用户),比如是否被谷歌处罚(manual action报告)、结构化数据是否恰当、移动端友好性等。
所以我们可以在GSC看到这类数据:
- 检查谷歌是否可以抓取自己的网站
- 检查索引问题,提交收录申请
- 查看网站的谷歌自然搜索流量,哪些搜索词触发了排名、搜索词的点击率等
- 显示哪些网站链接到了自己的网站
- 结构化数据问题等报告。
所以GSC和GA数据不同的第一个原因是,它们的功能不一样,导致数据计算方式或者着重的方式(对各自而言更重要的数据可能更准)不一样。
但其实数据可能是准确的,只是它们显示方式不同。
比如同样是100个用户,在GA和GSC显示的数据可能不同。
所以下面具体聊聊:
为什么 GSC 和 GA数据对不上? 1. JavascriptGA只会从在浏览器启用了 Javascript 的用户那里收集到的数据。
而无论浏览器是否启用了 Javascript,GSC都会收集数据。
2. GA的趋势随着用户(国家)对隐私越来越重视(比如欧洲的GDPR和ITP)和隐私政策不断地跟新,GA的跟踪功能会越来越多地受限制。
例如,DuckDuckGo 的浏览器插件和 Mozilla 的 Firefox 浏览器都有机会阻止GA的数据收集。
而GSC的数据能正常收集,或者说受的限制远比GA要小。
3. 时间延迟GSC的数据会延迟几天,而 GA可以在几秒钟后更新数据。
GSC报告的延迟可能会导致对比双方数据的时候产生差异。
4. 谷歌本身的限制抛开大环境的影响,谷歌本身也会主动地对数据进行一定程度的过滤。
谷歌GSC官方就说为了保护用户隐私,报告不会显示所有数据:
 图片来源:谷歌帮助中心
图片来源:谷歌帮助中心
对源数据的处理可能会导致这些统计数据与其他工具中的统计数据有所不同。
出于隐私原因,GSC 会忽略部分的搜索流量。
5. 时区差异GA是根据我们在后台设置所在的时区展示数据。
在设置中可以为网站设置首选时区:
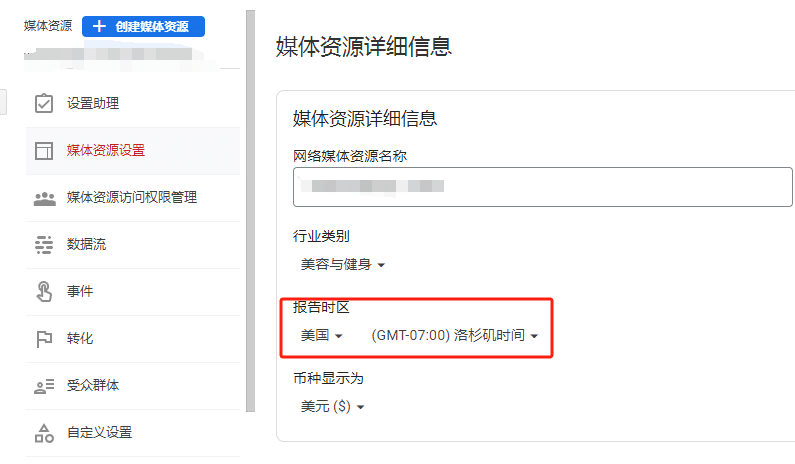 图片来源:谷歌帮助中心
图片来源:谷歌帮助中心
而GSC 则是根据太平洋夏令时间(PDT)展示数据,而不管我们的网站设置在哪个国家或时区。
这就很可能出现这样一种情况:GSC将数据分配到一个时区,而 GA将数据分配到另一个时区。
这将对数据报告产生很大影响,所以GSC和 GA之间的流量数据很大可能会存在差异。
那我们该看哪个工具的数据呢?所以嘛,GSC和GA的报告和数据确实存在差异。
但数据存在差异并不表明数据有问题。
只是它们是两种不同的产品,针对的功能也不一样,所以它们用了不同的方式展示数据而已。
那我们该看哪个工具的数据呢?
其实我们只要特定的指标用固定的工具查看就好了。
比如经常有读者问,做SEO看自然流量,是看GSC的点击数据好,还是GA的organic好?
我就会回答,只要一直固定一个工具看、去衡量就好。
比如固定用GSC的数据去衡量自然流量的表现,就不看GA的,反之亦然。当然,也可以同时拉另一个工具的数据做参考,但只是参考,没必要花时间去缩小它们的差异。
因为数据本来就不存在准不准的问题——因为出于隐私原因,数据肯定不准。而且能影响的变量也很多,没必要纠结。
希望这篇文章能帮助大家解决到一个工作上不必要的纠结点。
Peace Out!
 收录于以下专栏
收录于以下专栏  谷歌SEO 1 个内容 · 2 人关注 查看专栏 独立站 37 个内容 · 8 人关注 查看专栏 跨境电商 37 个内容 · 8 人关注 查看专栏
谷歌SEO 1 个内容 · 2 人关注 查看专栏 独立站 37 个内容 · 8 人关注 查看专栏 跨境电商 37 个内容 · 8 人关注 查看专栏 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!
内容声明:本文中引用的各种信息及资料(包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主体(包括但不限于公司、媒体、协会等机构)的官方网站或公开发表的信息。部分内容参考包括:(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供参考使用,不准确地方联系删除处理!本站为非盈利性质站点,发布内容不收取任何费用也不接任何广告!
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理,本文部分文字与图片资源来自于网络,部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理!的,若有来源标注错误或侵犯了您的合法权益,请立即通知我们,情况属实,我们会第一时间予以删除,并同时向您表示歉意,谢谢!
